Evolution of the Stethoscope: Advances with the Adoption of Machine Learning and Development of Wearable Devices
Article information

Abstract
The stethoscope has long been used for the examination of patients, but the importance of auscultation has declined due to its several limitations and the development of other diagnostic tools. However, auscultation is still recognized as a primary diagnostic device because it is non-invasive and provides valuable information in real-time. To supplement the limitations of existing stethoscopes, digital stethoscopes with machine learning (ML) algorithms have been developed. Thus, now we can record and share respiratory sounds and artificial intelligence (AI)-assisted auscultation using ML algorithms distinguishes the type of sounds. Recently, the demands for remote care and non-face-to-face treatment diseases requiring isolation such as coronavirus disease 2019 (COVID-19) infection increased. To address these problems, wireless and wearable stethoscopes are being developed with the advances in battery technology and integrated sensors. This review provides the history of the stethoscope and classification of respiratory sounds, describes ML algorithms, and introduces new auscultation methods based on AI-assisted analysis and wireless or wearable stethoscopes.
Introduction
Auscultation has long been used for the examination of patients because it is non-invasive, and provides valuable information in real-time [1-3]. Thus, the stethoscope is a primary diagnostic device especially for respiratory diseases [4]. Abnormal respiratory sounds provide information on pathological conditions involving the lungs and bronchi. However, the importance of auscultation is declining, in part due to the development of other diagnostic methods [5] but mainly because of the largest drawback of auscultation, i.e., its inherent subjectivity. The discrimination of abnormal sounds largely depends on the experience and knowledge of the listeners; this problem is being addressed by implementing a standardized system to analyze respiratory sounds accurately. For example, lung sounds can be recorded with a digital stethoscope and then shared [6]. Artificial intelligence (AI)-assisted auscultation and digital stethoscopes that make use of machine learning (ML) algorithms are changing the clinical role of auscultation [7-24].
Another limitation of existing stethoscopes with respect to auscultation is the impossibility of remote care for patients with chronic diseases who are confined to nursing facilities or home, or cannot readily access a doctor [7,24]. Auscultation requires contact between the stethoscope and patient’s body, and thus cannot be used remotely. The utility of non-face-to-face treatment was well demonstrated by the coronavirus disease 2019 (COVID-19) crisis [25-28]. This limitation is being addressed by recent advances in battery technology and integrated sensors, which have led to the development of wireless stethoscopes that can be worn by the patient and allow auscultation to be done remotely [29-32].
In this review, we briefly examine the history of the stethoscope, from its development to the present, and the various respiratory sounds. We then describe ML in a step-by-step manner, including its use in analyzing respiratory sounds. New auscultation methods based on AI-assisted analysis and wireless or wearable stethoscopes are considered, and the results of recent clinical trials examining AI-based analyses of respiratory sounds are discussed.
Classification of Respiratory Sounds
Respiratory sounds are generated by airflow in the respiratory tract and may be normal or abnormal (Table 1). Normal respiratory sounds include tracheal, bronchovesicular, and vesicular sounds [33,34]. Abnormal sounds are caused by diseases of the lungs or bronchi [34,35] and can be identified according to their location, mechanism of production, characteristics (pitch, continuity, time when typically heard), and acoustic features (waveform, frequency, and duration) [36]. Crackles are short, discontinuous, explosive sounds that occur on inspiration and sometimes on expiration [3,37]. Coarse crackles are caused by gas passing through an intermittent airway opening and are a feature of secretory diseases such as bronchitis and pneumonia [38]. Fine crackles are induced by an inspiratory opening in the small airways and are associated with interstitial pneumonia, idiopathic pulmonary fibrosis (IPF), and congestive heart failure [39]. Stridor is a high-pitched, continuous sound produced by turbulent airflow through a narrowed airway of the upper respiratory tract [3]. It is usually a sign of airway obstruction and thus requires prompt intervention. Wheezes are produced in the narrowed or obstructed airway [3], are of high frequency (>100 to 5,000 Hz), and have a sinusoidal pattern of oscillation [40]. They usually occur in obstructive airway diseases such as asthma and chronic obstructive pulmonary disease (COPD) [38]. Rhonchi are caused by narrowing of the airways due to the secretions and may thus disappear after coughing [3]. In patients with pleural inflammation such as pleurisy, the visceral pleura becomes rough and friction with the parietal pleura generates crackling sounds, i.e., friction rub [41]. Sometimes, a mixture of two or more sounds or noises are heard. Respiratory sounds may also be ambiguous such that even an expert will have difficulty in distinguishing them accurately. In these challenging situations, an AI-assisted stethoscope would be useful.

Classification of normal and abnormal respiratory sounds
Development of Stethoscopes
The word “stethoscope” is derived from the Greek words stethos (chest) and scopos (examination). In the 5th century B.C., Hippocrates listened to chest sounds to diagnose disease (Table 2) [1,6,29-32,42-48]. In the early 1800s, before the development of the stethoscope, physical examinations included percussion and direct auscultation, with doctors placing an ear on the patient’s chest to listen to internal sounds. In 1817, the French doctor Rene Laennec invented an auscultation tool. Over time, the stethoscope gradually became a binaural device with flexible tubing and a rigid diaphragm. Throughout the 1900s, minor improvements were made to reduce the weight of the stethoscope and improve its acoustic quality. Electronic versions of the stethoscope allowed further sound amplification. Since the 2000s, with advances in battery technology, low power embedded processors, and integrated sensors, wearable and wireless digital stethoscopes are emerging; some devices are now able to record and transmit sound, which can then be automatically analyzed using AI algorithms.

History of stethoscope development
Artificial Intelligence
1. Overview
The development of an AI model typically consists of four steps (although in the case of deep learning, three steps are involved), as follows (Figure 1).
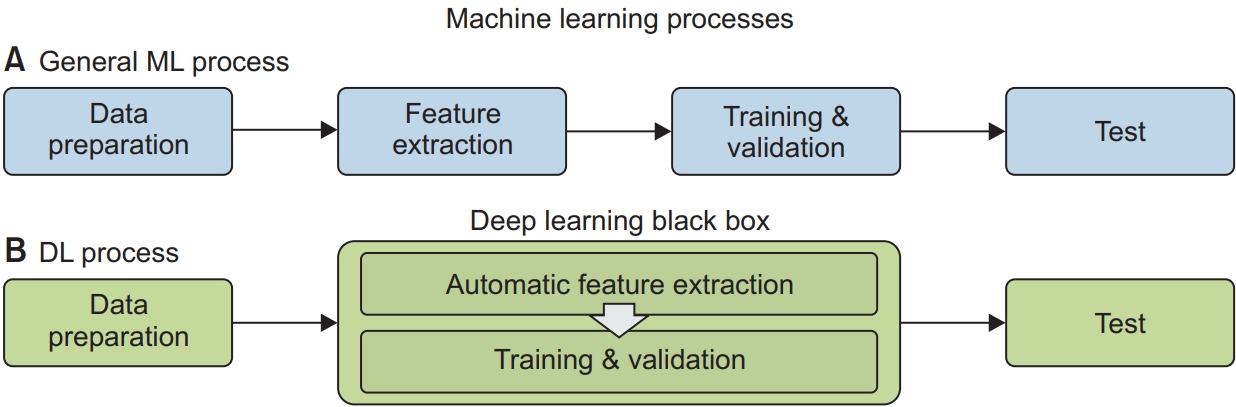
Machine learning processes. (A) General machine learning process. (B) Deep learing (DL) process.
1) Data preparation
A dataset appropriate for the target, i.e., the output of the model is obtained. During preprocessing, outliers are pre-screened and missing values are augmented from the given data. Since more data results in higher accuracy and better generalization, after data preprocessing, whether the data are still sufficient for model construction should be confirmed.
2) Feature extraction
After data preparation, features appropriate for the target are extracted. All available features, the relevance of which is determined based on expert insights, should be extracted, but even seemingly uncorrelated features might improve model performance. However, there may also be competition between the features of interest. In such cases, dimensional reduction in the feature domain will greatly improve the computational performance and efficiency of the model. In deep learning, this step is merged with the subsequent training and validation steps. Deep learning is designed for automatic feature generation based on the data, but the process leading to the model’s output is poorly understood such that deep learning is called a “black box”-type algorithm.
3) Training and validation
These key steps in ML and data driven algorithms are performed using support vector machine (SVMs), decision trees, and deep learnings. From the prepared data, the algorithms train the model by optimizing the cost function for the target. An appropriate and efficient cost function is therefore an important task in model construction. After the model has been trained, it is validated using data prepared from the training data. The most well-known validation method is n-fold validation.
4) Testing
After a model with the desired performance is obtained, it is run using a test dataset, which is also prepared either exclusively from the training and validation dataset or with the addition of new data. A model that performs better during training and validation than testing, usually suffers from overfitting; data generalization is one of the solutions to this problem.
2. AI-based classification of respiratory sounds
Most current AI algorithms for the identification of respiratory sounds are data driven, i.e., trained from a given dataset. In this approach, the performance of the AI algorithms is highly dependent on the data type and preparation. Thus far, deep learning methods have performed best; however, regardless of the method, clinicians should understand how AI-based respiratory sound analysis applies to clinical practice. Studies assessing the utility of ML and deep learning to analyze respiratory sounds are summarized in Table 3.

Recent studies performing AI-based analyses of respiratory sounds
In a previous study, we developed a deep learning algorithm of respiratory sounds [49], using convolutional neural network (CNN) classifier with transfer learning method for appropriate feature extraction. The model detected abnormal sounds among 1,918 respiratory sounds recorded in a routine clinical setting; the detection accuracy was 86.5%. Furthermore, the model was able to classify abnormal lung sounds, such as wheezes, rhonchi, and crackles with an accuracy of 85.7%. Chen et al. [18] proposed a novel deep learning method for the classification of wheeze, crackle, and normal sounds using optimized S-transform (OST) and deep residual networks (ResNets) to overcome the limitations of artifacts and constrained feature extraction methods. The proposed ResNet using OST had an accuracy of 98.79%, sensitivity of 96.27%, and specificity of 100% for the classification of wheeze, crackle, and normal respiratory sounds.
An ML-based analysis using artificial neural networks (ANNs) was applied to identify four respiratory sounds, including wheezes, rhonchi, and coarse and fine crackles [20]. The AI approach was more efficient than an evaluation by five physicians. In another study using ANNs, the accuracy for classifying crackle, rhonchi, and normal respiratory sounds was 85.43% [12]. The classification performance of ANNs for pediatric respiratory sounds was independently validated. Detection accuracy was high for crackles and wheezes, at 95% and 93% respectively [10]. A recent study developed a semi-supervised deep learning algorithm to identify wheezes and crackles in 284 patients with pulmonary diseases [23]. The area under the receiver characteristic curve obtained with the algorithm was 0.86 for wheezes and 0.74 for crackles. The study showed that a semi-supervised algorithm with SVM enables the analysis of large datasets without the need for additional labeling of lung sounds.
Analysis of respiratory sounds using a deep learning algorithm (deep belief networks [DBNs]) successfully distinguished patients with COPD from healthy individuals [8]. The proposed DBN classifier also distinguished COPD from non-COPD patients with accuracy, sensitivity, and specificity, values of 93.67%, 91%, and 96.33%, respectively. The authors concluded that a deep learning-based model could aid the assessment of obstructive lung diseases, including COPD. Using a decision tree forest algorithm with additional wavelet features, Fernandez-Granero et al. [50] investigated the respiratory sounds recorded in 16 COPD patients telemonitored at home with a respiratory sensor device. The detection accuracy of 78.0% demonstrated the potential of the proposed system for early prediction of COPD exacerbations, which would allow patients to obtain timely medical attention.
A recent study investigated the use of deep learning to recognize pulmonary diseases based on respiratory sounds [13]. Electronically recorded lung sounds were obtained from controls and patients suffering from asthma, COPD, bronchiectasis, pneumonia, and heart failure; the classification accuracy of the deep learning algorithm was 98.80%, 95.60%, 99.00%, 100%, 98.80%, and 100%, respectively. In that study, the data were initially preprocessed and used to train two deep learning network architectures, i.e., a CNN and bidirectional long short-term memory network (BDLSTM), attained a precision of 98.85%. Other studies have also applied deep learning models to classify pulmonary diseases based on respiratory sounds [51]. A study using the International Conference on Biomedical and Health Informatics (ICBHI) database used crackles, wheezes, and both as the basis for AI-guided diagnosis of pneumonia, lower respiratory tract infection (LRTI), upper respiratory tract infection (URTI), bronchiectasis, bronchiolitis, COPD, and asthma [52]. Respiratory sounds representing those diseases were synthesized using a variety of variational autoencoders. The results showed that unconditional generative models effectively evaluated the synthetic data. The sensitivity of multi-layer perceptron, CNN, long short-term memory (LSTM), Res-Net-50, and Efficient Net B0 was 97%, 96%, 92%, 98%, and 96%, respectively. A hybrid model combining CNN and LSTM was also proposed for accurate pulmonary disease classification [53]. Four different sub-datasets were generated from the ICBHI [52] and King Abdullah University Hospital [54]. The four datasets contained data asthma, fibrosis, bronchitis, COPD, heart failure, heart failure+COPD, heart failure+lung fibrosis, lung fibrosis, pleural effusion, and pneumonia. The best results were obtained with the hybrid model, which had the highest classification accuracy (99.81%) for 1,457 respiratory sounds from controls and patients with asthma, bronchiectasis, bronchiolitis, COPD, LRTI, pneumonia, and URTI. By expanding the number of training datasets, the overall classification accuracy improved by 16%.
These studies suggest that AI-based respiratory sound analysis can provide an innovative approach in the diagnosis of respiratory diseases. Although there are still limitations such as the interpretations of complex sounds and data dependency, moreover, undesired noises exist, AI-based algorithms are expected to play a key role in supporting clinicians to evaluate respiratory diseases in the future. Additionally, noise reduction or removal and data standardization are needed for obtaining enhanced prediction performance of AI algorithms.
Clinical Trials Using Digital Stethoscopes and Artificial Intelligence
Many ongoing studies are investigating the use of digital stethoscopes in combination with AI, beginning with the classification of respiratory sounds as normal or abnormal. AI algorithms are then developed to analyze the recorded sounds for the detection of COPD, asthma, IPF, and other lung diseases (e.g., using the StethoMe electronic stethoscope, Poznań, Poland). Other clinical trials are examining the use of AI to screen COVID-19 patients based on their voice, breaths, and cough, and testing the feasibility of smart stethoscopes for remote telemedicine and the monitoring patients with respiratory diseases (by checking respiratory and cough sounds) (Table 4).

Ongoing clinical trials using digital stethoscopes and artificial intelligence
With advances in mechanical technology and AI, smart stethoscopes able to analyze and classify respiratory sounds will soon be implemented in many clinical fields. This may lead to renewed awareness of the clinical importance of auscultation, which has been underestimated since the advent of image technologies such as computed tomography and sonography.
New Devices
Wireless and wearable stethoscopes, which are gradually becoming commercially available, are particularly useful for treating patients who must be isolated, such as those with COVID-19, in whom auscultation cannot be performed with a regular stethoscope. For example, a wireless stethoscope with a Bluetooth connection system can be used to monitor hospitalized patients with severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) pneumonia [55]. More advanced wearable stethoscopes may improve the monitoring of patients with pulmonary diseases. Zhang et al. [55] developed a wearable, Bluetooth 5.0 Low Energy (LE)-enabled, multimodal sensor patch that combines several modalities, including a stethoscope, ambient noise sensing, electrocardiography, and impedance pneumography, thus providing multiple types of clinical data simultaneously. Lee et al. [56] developed a soft wearable stethoscope with embedded ML and evaluated its ability to classify respiratory sounds; the feasibility of wearable smart stethoscopes was demonstrated. Joshitha et al. [57] designed a Wi-Fi-enabled contactless electronic stethoscope. The prototype, which contained a receiver module and circuit diagram, demonstrated the potential of this novel platform for use in smart stethoscopes. Recently, a smart stethoscope with contactless radar measurement ability has been introduced as an advanced method for the acquisition of respiratory sounds for use in many clinical settings. An important point in developing a new stethoscope is to reduce the motion artifact caused by the lack of adhesion between the rigid stethoscope and the patient’s dry skin. Since it leads to inaccurate diagnosis of breath sounds, there are attempts to reduce it by making the stethoscope of bendable materials or attaching the stethoscope to the body through bandages (Table 5) [29,55-58].

Recently developed wireless and wearable stethoscopes
Conclusion
With the development of digital stethoscopes and sound transmission technology, it has become possible to record and share respiratory sounds and accurately distinguish them using ML algorithms. Advances in battery technology, embedded processors with low power consumption, integrated sensors, Wi-Fi, and radar technology are contributing to the development of stethoscopes and other wireless and wearable medical devices. In the case of stethoscopes, these significant modifications have overcome the limitations of existing models. Importantly, they allow the identification of respiratory diseases without a specialist, thereby enhancing the clinical effectiveness of auscultation. Accurate auscultation can result in more rapid diagnosis and earlier treatment, in addition to reducing the burden of radiation exposure and high examination costs by avoiding unnecessary imaging tests. As the use of telemedicine has expanded, driven by its successful implementation during the COVID-19 pandemic, the monitoring of chronic respiratory diseases in the hardto-reach patients will be vastly improved.
With the development of wearable stethoscopes and the transmission of breath sounds through Bluetooth, there are attempts to continuously monitor the breath sounds of critically ill patients in the intensive care unit. In a study comparing continuous auscultation using a wearable stethoscope with intermittent auscultation using a conventional stethoscope for wheeze detection, extending the duration of auscultation using a wearable stethoscope even in a noisy environment showed comparable performance to the conventional auscultation [59]. Another study showed that the quantification of abnormal respiratory sounds could predict complications after extubation [60]. In addition, a study was attempted to detect the position of the double-lumen tube through the strength of the respiratory sound in patients undergoing lung surgery [61].
However, smart stethoscope must still overcome several problems. Coexisting noises make it difficult to precisely discriminate respiratory sounds, such that noise filtering is important albeit challenging task. In addition, two or more sounds may be mixed and heard at the same time, which complicates their differentiation. Further refinement of deep learning algorithms may improve noise filtering, including the ability to distinguish the characteristics of coexisting sounds.
Point-of-Care Ultrasound (POCUS), which has been used for the diagnosis and treatment of various diseases since the 1990s, has also rapidly increased its use with the introduction of portable device, and is useful for primary care of patients along with stethoscopes [62]. Like a stethoscope, POCUS is non-invasive and can be performed right on the bed without moving the patient to the examination room. The combination of image-based POCUS and the sound-based stethoscope serves as an effective diagnostic tool in the clinical field [63-65].
In conclusion, the stethoscope is expected to develop through steady research in the future, and to be used as more popular medical devices through the application of AI analysis programs and development of wearable device. This breakthrough of stethoscope has the potential to pave the way for a future defined by personalized digital healthcare.
Notes
Authors’ Contributions
Conceptualization: Ha T, Chung C. Methodology: Lee SI. Investigation: Lee S. Writing - original draft preparation: Kim Y, Woo SD, Chung C. Writing - review and editing: Hyon YK. Approval of final manuscript: all authors.
Conflicts of Interest
No potential conflict of interest relevant to this article was reported.
Funding
This study was supported by a 2021-Grant from the Korean Academy of Tuberculosis and Respiratory Diseases, National Research Foundation of Korea (2022R1F1A1076515), and National Institute for Mathematical Sciences (NIMS) grant funded by the Korean government (No. B23910000).



